오차 역전파
- 순전파 : 입력 데이터를 입력층에서부터 출력층까지 정방향으로 이동시키며 출력 값을 예측해 나가는 과정
- 역전파 : 출력층에서 발생한 오차를 입력층 쪽으로 전파시키면서 최적의 결과를 학습해 나가는 과정
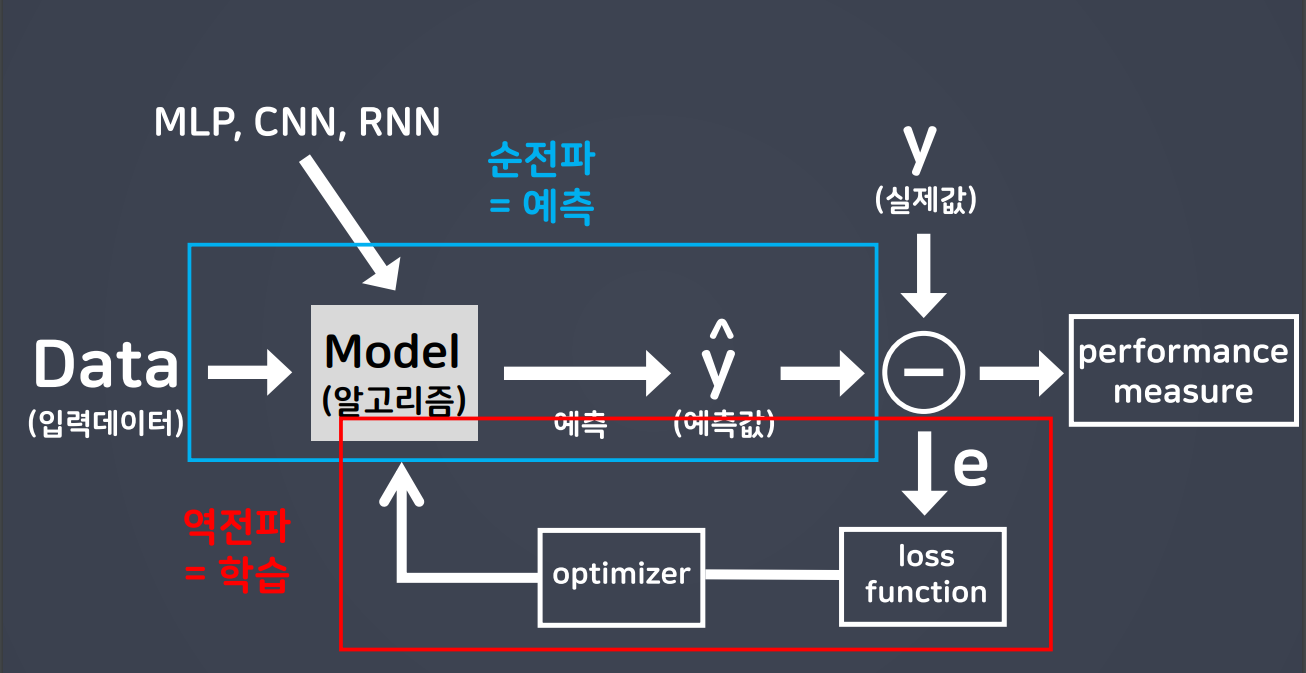
경사하강법
- 그 자리에서 loss가 작아지는 방향으로 이동하는 방법
- 즉, 비용함수(loss)의 기울기를 구하여 기울기가 낮은 쪽으로 계속 이동하여 값을 최적화 시키는 방법이다.
- 비용함수의 기울기 = loss 변화량 / w 변화량
- w값의 변화량에 따라 loss가 변화하는 정도
- 즉, 모델은 학습할 때, loss가 감소하는 w로 최적화한다.
- 최적화 함수(optimizer)가 경사하강법을 수행하면서 모델을 최적화한다.
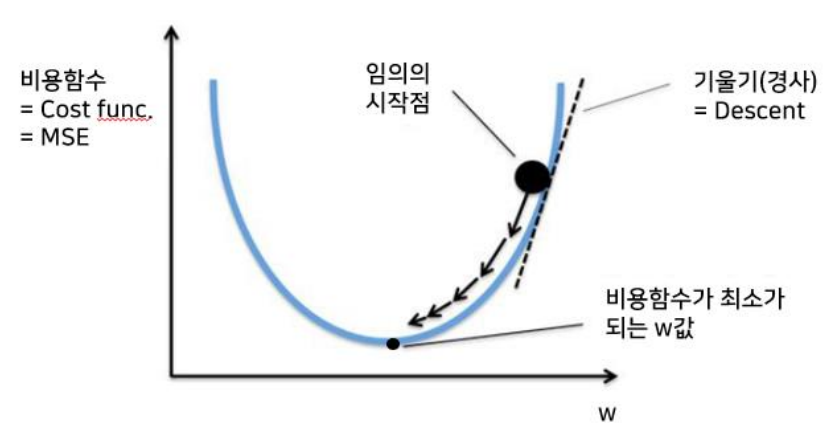
기울기 소실(Vanishing Gradient)
- 깊은 층을 만들어 보니 출력층에서 시작된 가중치의 업데이트(역전파)가 처음 층까지 잘 전달되지 않는 현상 발생
- 이를 기울기 소실이라고 함
- 시그모이드 함수의 특성 때문
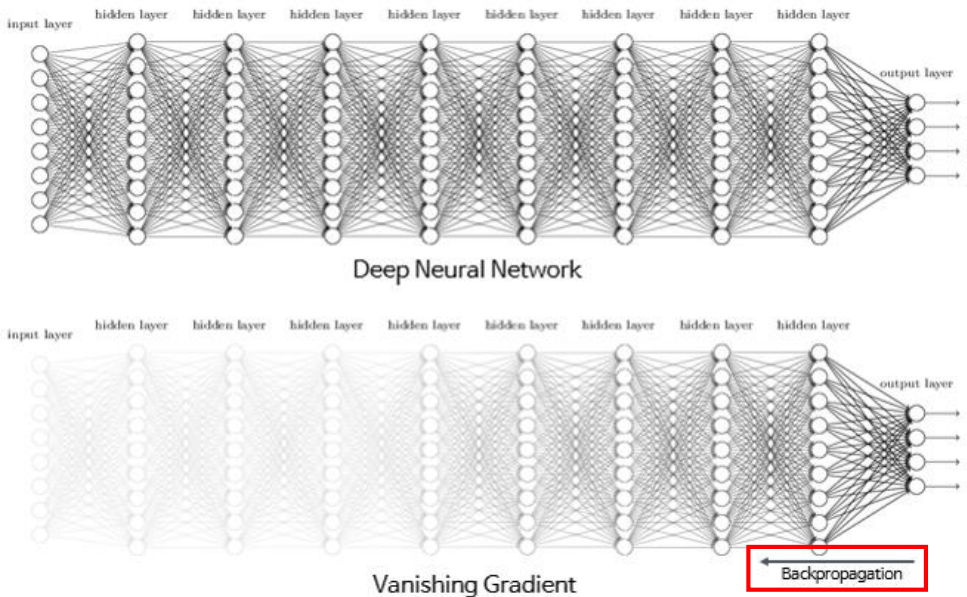
sigmoid의 문제점
- 시그모이드 함수를 미분하면 최대치는 약 0.3임
- 1보다 작기때문에 계속 곱하다 보면 0에 가까워져 가중치를 수정하기 어려워짐
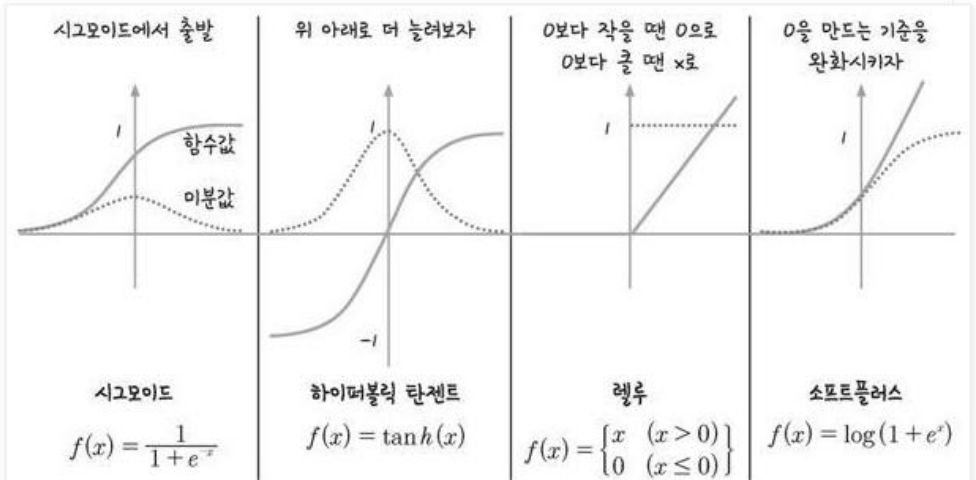
활성화 함수 종류
- sigmoid의 문제점을 해결하기 위해 다양한 활성화 함수가 존재
최적화 함수(Optimizer)의 종류
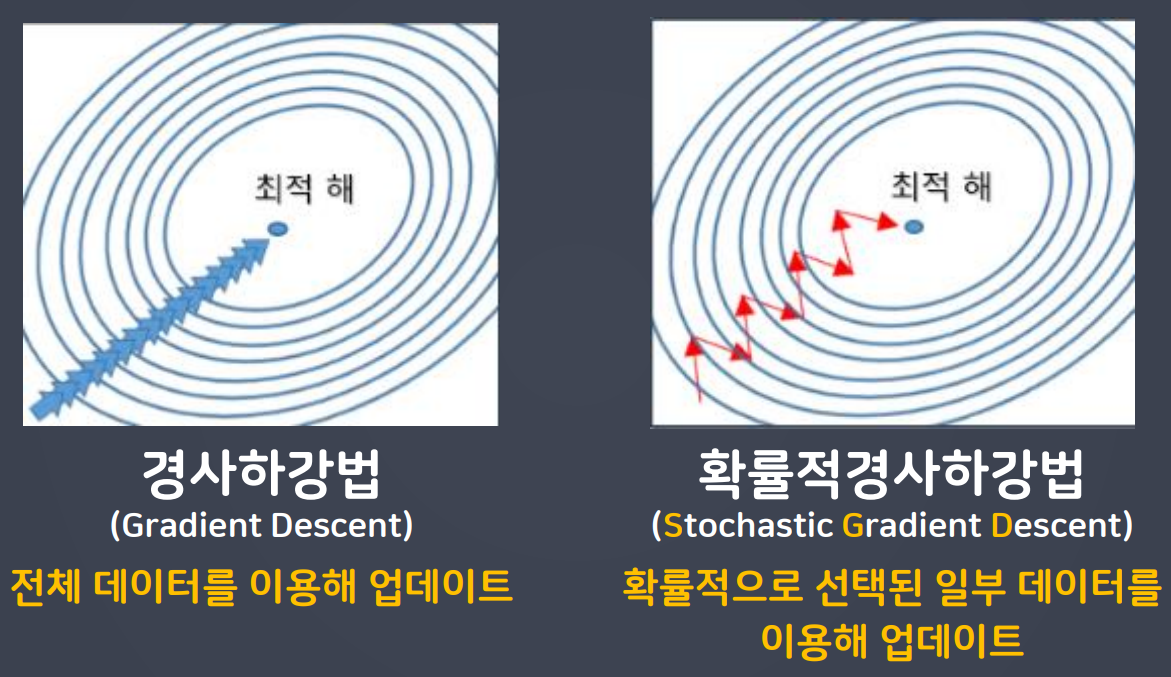
SGD(확률적 경사 하강법)
- 경사하강법은 전체 데이터를 이용해 업데이트 하는 방법이다
- 하지만, 실제로는 전체 데이터를 모두 활용하여 모델을 학습하기는 불가능(경사하강법은 이론상으로만 존재)
- SGD, 확률적 경사 하강법 : 확률적으로 선택된 일부 데이터를 이용해 업데이트
- SGD를 수행할 때 확률적으로 선택할 데이터 갯수 : batch_size로 결정한다
batch size
- 일반적으로 PC 메모리의 한계 및 속도 저하 때문에 대부분의 경우 한번의 epoch에 모든 데이터를 집어넣기 힘듦
- batch_size를 줄임
- 메모리 소모가 적음
- 학습 속도가 느림, 정확도는 높아짐
- batch_size를 높임
- 메모리 소모가 큼
- 학습 속도가 빠름, 정확도는 낮아짐
- batch_size의 디폴트 값은 32이며 일반적으로 32, 64가 많이 사용됨
모멘텀
- 경사 하강법에 관성을 적용해 업데이트함
- 현재 batch 뿐만 아니라 이전 batch 데이터의 학습결과도 반영하는 방법
- 개선된 모멘텀 방식으로는 네스테로프 모멘텀이 있다.
Adagrad(에이다그래드)
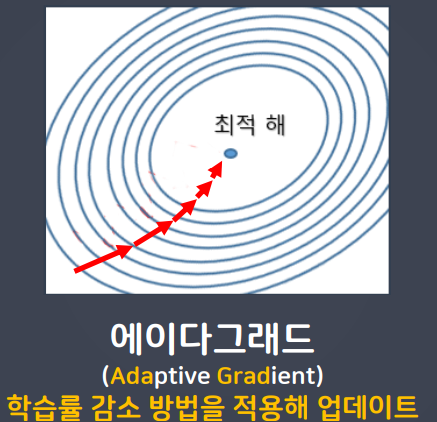
- 학습을 진행하면서 학습률을 점차 줄여가는 방법
- 처음에는 크게 학습하다가 조금씩 작게 학습함
- 학습을 빠르고 정확하게 할 수 있는 장점이 있다.
최적화 함수(Optimizer) 종류 한눈에 보기
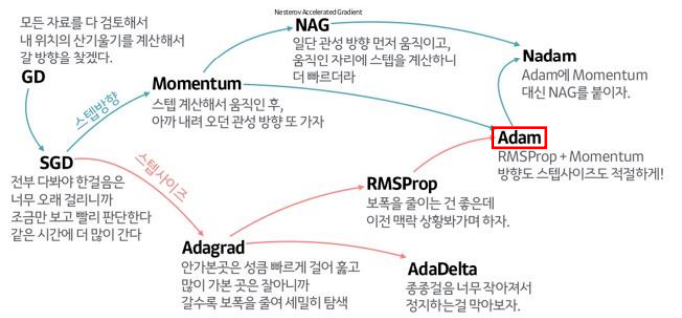
- 방향(스텝 방향)과 학습률(스텝 사이즈)을 모두 고려하는게 Adam
- Adam을 사용하면 기본은 간다

댓글남기기