
Tensorflow:: 다중분류_모델_만들기(3종류_동물)
목표
- CNN망 직접 설계하여 이미지 다중분류 하기(3개의 클래스)
- VGG16모델 전이학습 활용하여 모델 보완
- 전이학습 - 특성 추출 방식
- 전이학습 - 미세 조정 방식
- 데이터 증식(ImageDataGenerator 사용) 활용하여 모델 보완
구글에 고슴도치, 햄스터, 푸들을 검색한 결과로 나온 이미지 각 400장을 크롤링하여 저장해 놓은 npz 데이터를 활용한다.
저장된 npz 데이터를 활용하여 고슴도치, 햄스터, 푸들로 분류할 수 있는 CNN 모델 생성하기
생성한 NPZ 파일 로드
data = np.load('/content/drive/MyDrive/Colab Notebooks/2022GJAI_DL/GJAI_DL/data/animal.npz')
X_train = data['X_train']
X_test = data['X_test']
y_train = data['y_train']
y_test = data['y_test']
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((960, 224, 224, 3), (240, 224, 224, 3), (960,), (240,))
1. CNN 모델 만들기
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
- Conv2D : 2D 이미지 데이터에 대해 특징이 되는 부분들을 부각시켜줌
- input_shape : Input 데이터 크기(높이 ,넓이, 채널)
- filters : 필터의 갯수
- kernel_size : 필터의 크기
- padding=‘same’ : 원본 데이터의 크기에 맞게 알아서 패딩 적용(valid : 적용X)
- MaxPool2D : 2D 이미지 데이터에 대해 필요 없는 정보를 삭제(축소 샘플링)
- pool_size : 디폴트 값은 2(2 X 2)
# 모델 설계
cnn_model = Sequential()
# 특성 추출부(Conv층)
cnn_model.add(Conv2D(input_shape=(224, 224, 3), filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
# 특성 추출부(Pooling)
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))cnn_model.add(MaxPool2D())
# 분류기(MLP)
cnn_model.add(Flatten())
cnn_model.add(Dense(128, activation='relu'))
cnn_model.add(Dense(64, activation='relu'))
cnn_model.add(Dense(32, activation='relu'))
cnn_model.add(Dense(3, activation='softmax'))
생성한 CNN 모델 정보 확인하기
cnn_model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 224, 224, 128) 3584
max_pooling2d (MaxPooling2D (None, 112, 112, 128) 0
)
conv2d_1 (Conv2D) (None, 112, 112, 256) 295168
max_pooling2d_1 (MaxPooling (None, 56, 56, 256) 0
2D)
conv2d_2 (Conv2D) (None, 56, 56, 128) 295040
max_pooling2d_2 (MaxPooling (None, 28, 28, 128) 0
2D)
conv2d_3 (Conv2D) (None, 28, 28, 64) 73792
max_pooling2d_3 (MaxPooling (None, 14, 14, 64) 0
2D)
flatten_1 (Flatten) (None, 12544) 0
dense_5 (Dense) (None, 128) 1605760
dense_6 (Dense) (None, 64) 8256
dense_7 (Dense) (None, 32) 2080
dense_8 (Dense) (None, 3) 99
=================================================================
Total params: 2,283,779
Trainable params: 2,283,779
Non-trainable params: 0
_________________________________________________________________
모델 컴파일
cnn_model.compile(loss="sparse_categorical_crossentropy",
optimizer='Adam',
metrics=['acc']
)
모델 학습
h1 = cnn_model.fit(X_train, y_train, validation_split=0.2, epochs=50, batch_size=128)
학습 과정 시각화
plt.figure(figsize=(15, 5))
plt.plot(h1.history['acc'], label='acc')
plt.plot(h1.history['val_acc'], label='val_acc')
plt.legend()
plt.show()
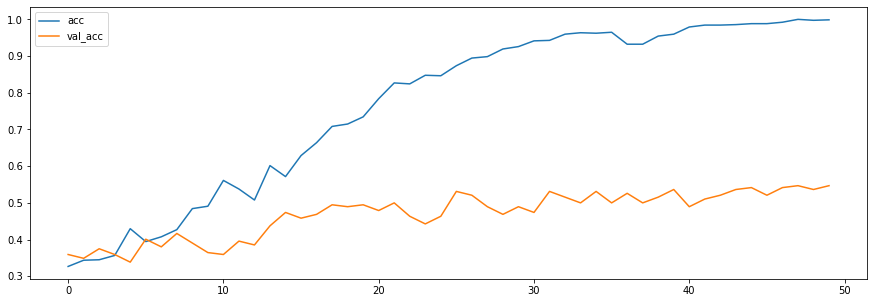
훈련 데이터에서는 정확도가 높지만, 검증셋에서 정확도가 매우 낮아지는 과적합 상태를 확인할 수 있다
정확도 외에 정밀도, 재현율, F1스코어 까지 확인해보기
- 모델의 예측결과는 각 클래스에 대한 확률값으로 나오기 때문에(softmax)
- 가장 높은 값의 인덱스를 반환해주는 np.argmax로 변환해서 점수 확인
from sklearn.metrics import classification_report
pred = cnn_model.predict(X_test)
print(classification_report(y_test, np.argmax(pred, axis=1)))
8/8 [==============================] - 2s 151ms/step
precision recall f1-score support
0 0.52 0.43 0.47 76
1 0.53 0.43 0.47 84
2 0.46 0.62 0.53 80
accuracy 0.50 240
macro avg 0.50 0.50 0.49 240
weighted avg 0.50 0.50 0.49 240
- precision(정밀도) : 모델이 True라고 분류한것 중 실제 True의 비율
- recall(재현율) : 실제 True인 것 중 모델이 True라고 예측한 비율
- accuracy(정확도) : 전체 중에서 모델이 옳게 예측한 비율
- f1-score : 정밀도와 재현율의 조화평균
정확도는 0.50으로 낮은 결과가 나왔다.
즉, 직접 설계한 CNN 모델로는 한번에 좋은 결과를 도출하기 어려움
구글에서 크롤링한 데이터이기 때문에, 좋은 결과를 얻기 위해 VGG16모델을 이용해 전이학습을 해보자.
2. VGG16 전이학습 수행
VGG16 모델 불러오기
from tensorflow.keras.applications import VGG16
pre_trained_model = VGG16(include_top=False,
weights='imagenet',
input_shape=(224, 224, 3)
)
- include_top=False : 불러온 모델의 MLP층(분류기)을 사용하지 않고 특성추출부만 사용(=특성 추출 방식)
- weights=‘imagenet’ : 이미지넷 챌린지 대회에서 학습한 해당 모델의 w,b값을 그대로 사용(default)
VGG16 모델 정보 확인해보기
pre_trained_model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
a. 전이학습 - 특성 추출 방식 이용
imagenet 챌린지 대회에서는 1000개의 이미지를 분류했으나 여기선 3개의 이미지를 분류할것이기 때문에 MLP층만 다르게 설정하는 특성 추출 방식으로 전이학습을 해보자
- VGG16의 특성추출부를 Sequential 객체에 추가하고, Flatten을 수행하여 직접 MLP를 정의해서 사용
- 이전에 생성했던 CNN 모델과 비교를 하기 위해 은닉층의 형태와 컴파일 작업을 동일한 형태로 수행했다.
cnn_model2 = Sequential()
# VGG16의 특성추출부
cnn_model2.add(pre_trained_model)
# MLP
cnn_model2.add(Flatten())
cnn_model2.add(Dense(128, activation='relu'))
cnn_model2.add(Dense(64, activation='relu'))
cnn_model2.add(Dense(32, activation='relu'))
cnn_model2.add(Dense(3, activation='softmax'))
cnn_model2.compile(loss="sparse_categorical_crossentropy",
optimizer='Adam',
metrics=['acc']
)
cnn_model2.compile(loss="sparse_categorical_crossentropy",
optimizer='Adam',
metrics=['acc']
)
cnn_model2.fit(X_train, y_train, validation_split=0.2, epochs=50, batch_size=128)
정확도 확인해보기
정확도만 먼저 비교해보기 위해 과적합 여부를 확인하기 위한 시각화는 수행하지 않았다.
pred = cnn_model2.predict(X_test)
print(classification_report(y_test, np.argmax(pred, axis=1)))
8/8 [==============================] - 3s 370ms/step
precision recall f1-score support
0 0.63 0.71 0.67 76
1 0.49 0.50 0.49 84
2 0.50 0.42 0.46 80
accuracy 0.54 240
macro avg 0.54 0.55 0.54 240
weighted avg 0.54 0.54 0.54 240
직접 생성한 CNN모델보다 결과는 좀 더 좋아졌지만, 아직 많이 부족하기 때문에 미세 조정 방식을 사용해보자.
b. 전이학습 - 미세 조정 방식 이용
이번엔, VGG16 특성추출부의 맨 마지막 부분의 합성곱층을 재학습하는 작업을 추가
VGG16 모델을 다시 불러온다.
pre_trained_model2 = VGG16(include_top=False,
weights='imagenet',
input_shape=(224, 224, 3)
)
pre_trained_model2.summary()
VGG16 모델의 Layer 이름에 접근해보기
모든 VGG16의 layer 이름을 확인해본 출력값이다.
for layer in pre_trained_model2.layers:
print(layer.name)
input_2
block1_conv1
block1_conv2
block1_pool
block2_conv1
block2_conv2
block2_pool
block3_conv1
block3_conv2
block3_conv3
block3_pool
block4_conv1
block4_conv2
block4_conv3
block4_pool
block5_conv1
block5_conv2
block5_conv3
block5_pool
맨 마지막 층인 block5_conv3 층만 재학습 시키고 나머지 Layer는 동결하기
layer.trainable 이용
for layer in pre_trained_model2.layers:
if layer.name == 'block5_conv3':
layer.trainable = True
else:
layer.trainable = False
pre_trained_model2.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 2,359,808
Non-trainable params: 12,354,880
_________________________________________________________________
summary 정보를 확인해보면 Trainable params에 block5_conv3의 param 갯수가 표시된다
즉, block5_conv3를 재학습 시킬 수 있다는 뜻이다.
- Trainable params : 재학습 시킬 수 있는 파라미터 갯수
MLP 설계
이제 MLP(분류기)층을 설계해준다. 이전에 수행했던 특성 추출 방식과 비교해보기 위해 동일한 형태로 설정해준다.
cnn_model3 = Sequential()
# VGG16의 특성추출부
cnn_model3.add(pre_trained_model2)
# MLP
cnn_model3.add(Flatten())
cnn_model3.add(Dense(128, activation='relu'))
cnn_model3.add(Dense(64, activation='relu'))
cnn_model3.add(Dense(32, activation='relu'))
cnn_model3.add(Dense(3, activation='softmax'))
cnn_model3.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 7, 7, 512) 14714688
flatten_5 (Flatten) (None, 25088) 0
dense_21 (Dense) (None, 128) 3211392
dense_22 (Dense) (None, 64) 8256
dense_23 (Dense) (None, 32) 2080
dense_24 (Dense) (None, 3) 99
=================================================================
Total params: 17,936,515
Trainable params: 5,581,635
Non-trainable params: 12,354,880
_________________________________________________________________
-
MLP를 직접 추가한 모델
Trainable params에 MLP 파라미터 갯수까지 추가된 걸 확인할 수 있다.
즉, 마지막 conv층 한개와 MLP(분류기)층을 다시 수행하고자 하는 목표에 맞게 재학습하게 될것이다.
모델 컴파일, 학습 및 결과
cnn_model3.compile(loss="sparse_categorical_crossentropy",
optimizer='Adam',
metrics=['acc']
)
cnn_model3.fit(X_train, y_train, validation_split=0.2, epochs=50, batch_size=128)
pred = cnn_model3.predict(X_test)
print(classification_report(y_test, np.argmax(pred, axis=1)))
8/8 [==============================] - 1s 155ms/step
precision recall f1-score support
0 0.85 0.79 0.82 76
1 0.80 0.86 0.83 84
2 0.91 0.90 0.91 80
accuracy 0.85 240
macro avg 0.85 0.85 0.85 240
weighted avg 0.85 0.85 0.85 240
VGG16 모델을 미세 조정 방식으로 학습해본 결과 정확도는 0.85로 비교적 좋은 결과가 나왔다.
즉, VGG16모델을 전이학습을 진행한 결과 직접 설계한 CNN모델에 비해 훨씬 결과가 잘 나오는 것을 확인할 수 있다.
3. 데이터 증강(Data Augmantation)
- 기존 이미지와 유사한 이미지를 추가로 생성하여 학습시 반영해주는 데이터 증식 기법
ImageDataGenerator
- 이미지 데이터를 생성하기 위한 조건을 설정할 수 있다.
- rotation_range : 이미지 회전 각도 설정
- width_shift_range : 수평(x축) 이동 범위 설정
- height_shift_range : 수직(y축) 이동 범위 설정
- zoom_range : 축소/확대 비율 설정
- horizontal_flip : 수평 방향으로 뒤집기 여부 설정
- fill_mode : 이미지가 변형되면서 비는 공간에 어떻게 픽셀로 채워줄지(nearest: 가장 가까운 픽셀로 채우기)
ImageDataGenerator 객체 생성
- 필요한 설정을 파라미터로 설정함
from tensorflow.keras.preprocessing.image import ImageDataGeneratoraug = ImageDataGenerator(rotation_range=30, width_shift_range=0.2, # 20% 내외 수평이동 height_shift_range=0.2, # 20% 내외 수직이동 zoom_range=0.2, # 0.8 ~ 1.2배로 축소/확대 horizontal_flip=True, # 수평방향으로 뒤집기 fill_mode='nearest' )
VGG16 모델 불러오기
- 목적에 맞게 학습시키기 위해 마지막 합성곱층 외에 동결시키기(전이학습 - 미세 조정 방식)
- VGG16의 마지막 합성곱층 이름은 block5_conv3로 확인할 수 있음
pre_trained_model3 = VGG16(include_top=False, weights='imagenet', input_shape=(224, 224, 3) )for layer in pre_trained_model3.layers: if layer.name == 'block5_conv3': layer.trainable = True else: layer.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 0s 0us/step
MLP(분류기) 정의하기
- 목적에 맞게 입력층, 은닉층, 출력층 생성
- 활성화함수 설정
cnn_model4 = Sequential()# VGG16의 특성추출부cnn_model4.add(pre_trained_model3)# MLPcnn_model4.add(Flatten())cnn_model4.add(Dense(128, activation='relu'))cnn_model4.add(Dense(64, activation='relu'))cnn_model4.add(Dense(32, activation='relu'))cnn_model4.add(Dense(3, activation='softmax'))
모델 컴파일하기
cnn_model4.compile(loss='sparse_categorical_crossentropy', optimizer='Adam', metrics=['acc'])
ImageDataGenerator로 설정한 조건으로 모델 학습
- ImageDataGenerator를 사용하여 학습하는 방법
- .flow(x, y)
- .flow_from_directory(directory)
- aug.flow() : ImageDataGenerator로 설정한 조건으로 생성된 이미지로 학습에 적용시켜준다.
- steps_per_epoch = (훈련 샘플수 / 배치 사이즈) : 제너레이터로부터 얼마나 많은 샘플을 뽑을 것인지 결정
- steps_per_epoch를 (X_train 길이 / batch_size) 즉, 7.5로 설정이 되면 한 epoch당 128개의 이미지를 활용하므로(batch_size때문에) 1epoch당 총 960개의 데이터를 활용하게 된다.
- 1epoch 때는 증강된 이미지 960개로 학습, 2epoch떄는 960개 추가되어 총 1920개로 학습
cnn_model4.fit(aug.flow(X_train, y_train, batch_size=128),
steps_per_epoch=len(X_train) / 128,
epochs=50
)
from sklearn.metrics import classification_report
pred = cnn_model4.predict(X_test)
print(classification_report(y_test, np.argmax(pred, axis=1)))
8/8 [==============================] - 1s 156ms/step
precision recall f1-score support
0 0.80 0.93 0.86 76
1 0.96 0.79 0.86 84
2 0.89 0.91 0.90 80
accuracy 0.88 240
macro avg 0.88 0.88 0.87 240
weighted avg 0.88 0.88 0.87 240
- ImageDataGenerator로 데이터 증식을 해서 학습하면 정확도가 약 88%로 더 나은 결과를 확인할 수 있음
- 데이터의 수가 적을 경우 데이터 증강을 진행한 후 정확도가 더 향상됨
- 데이터의 종류에 따라 정확도 개선의 정도는 다를 수 있음
댓글남기기