
객체 탐지 기술 정리
객체 탐지란
- 이미지 내에서 객체(사람, 사물 등)를 감지해 내는 것

평가지표
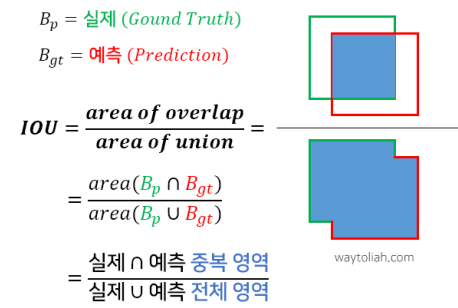
IoU(Intersection over Union)
- 이미지 내에 있는 하나의 객체를 탐지할 때 사용하는 평가지표이다.
- 실제 객체 면적과 모델이 예측한 면적의 (교차 영역 / 전체 영역) X 100
- 범위는 0 ~ 1.0 사이 (일반적으로 0.5가 넘으면 맞게 예측했다고 판단)
mAP(mean Average Precision)
- 한 이미지에서 여러 개의 객체(클래스)를 찾을 때 사용되는 평가지표이다.
- 각 객체(클래스)별 평균 정밀도(AP)를 계산한 후 클래스 전체에 대한 평균(mean)을 구하는 방식으로 범위값은 0 ~ 1.0 사이
- IoU 기준에 따라 mAP는 달라진다(IoU가 높으면 mAP는 낮아짐)
평균 정밀도(AP)
- 일반적으로 정밀도와 재현율(Recall)은 반비례 관계이다.
- 두 값을 모두 고려하여 모델의 성능을 판단하는 것이 합리적이다.
- 재현율의 11개 지점(0.0 ~ 1.0)에 대해 정밀도를 구해서(11점 보간법) 평균을 낸 것이 AP이다.
객체 탐지 알고리즘
1. Traditional Detection Methods
-
슬라이딩 윈도우(Sliding Window)
고정된 크기의 Window(=초록박스)로 이미지의 좌상단부터 우하단으로 일일이 객체를 검출해 나가는 방식
-
문제점
객체가 없는 영역도 무조건 Sliding해야 하며 여러 Scale의 이미지를 스캔하여 검출하는 방식이므로 수행시간은 늘고, 검출성능은 떨어진다.
2. Two-stage detector
-
영역추정(Region Proposal)과 탐지(Detection) 두 단계를 따로 수행하는 방식
Sliding Window의 비효율성으로 인해 R-CNN 알고리즘에서는 객체가 있을 법한 2000개의 영역을 찾고 그 영역에 대해서만 객체를 탐지하는 두 단계를 제안함
대표적으로는 R-CNN, Fast R-CNN, Faster R-CNN 모델이 있음
-
영역추정의 문제점
객체들이 각기 다른 크기와 형태를 가지고 있다면 후보 영역을 찾는 정확도가 떨어지게 됨
영역추정의 정확도를 향상시키기 위해 미리 이미지에서 객체 영역을 분할해 두면 후보 영역을 찾기가 더 쉽지 않을까 연구 진행
-
선택적 검색(Selective Search)
영역추정의 문제점을 해결하기 위해 고안된 방법
- 처음에는 분할된 모든 부분들을 Bounding box로 만들어 리스트에 추가
- 색상, 무늬, 크기, 형태에 따라 유사도가 비슷한 부분들을 그룹핑(Bbox 개수 감소)
- 1, 2단계를 계속 반복
3. One-stage detector
Two-stage detector는 Selective search 방식으로 인해 과거 대비 높은 정확도로 객체 탐지가 가능했지만, 여전히 낮은 속도로 실시간 적용은 어려웠음
One-stage detector는 영역추정과 객체탐지를 통합해 한 번에 수행
가장 큰 장점은 탐지 속도의 획기적인 향상으로 실시간 탐지가 가능하다.
YOLO(You Only Look Once)
- 대표적인 One-stage detector 방식 실시간 객체 검출 알고리즘
- 객체 영역 판단과 객체 인식을 동시에 진행하는 방식
- 기존 CNN은 이미지 전체를 하나의 레이블(클래스)로 표시한다면, Yolo는 이미지 내에 특정한 위치(영역 추정)와 객체 탐지를 동시에 진행한 후, 이를 설정된 레이블로 표시해줌
- 16년 version1부터 22년 version7까지 오픈소스로 출시됨
- Yolo v1(GoogLeNet 적용)은 Two-stage detector의 Faster RCNN(vgg16 적용)보다 6배 빠른 속도로 논문에 기재됨
YOLO(You Only Look Once) - v1
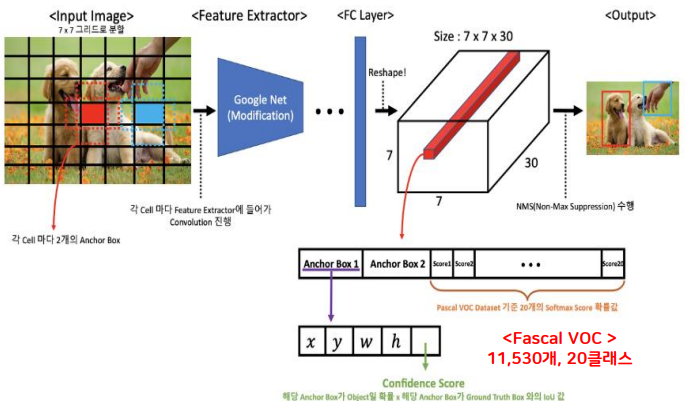
- 입력 이미지(448x448x3)를 7x7 Grid 영역으로 나눔
- 각 Grid cell당 2개의 Bounding Box를 생성(총 98개)
- 각각의 Bbox는 x, y, w, h와 confidence로 구성됨
- x, y는 Bbox의 중심점, w, h는 너비, 높이 ex) x가 cell의 가장 왼쪽에 있다면 0이고 y가 cell의 중간에 있다면 0.5 ex) 바운딩 박스의 w가 이미지 전체 너비의 절반이라면 w는 0.5
- Confidence는 Bbox가 객체를 포함한다는 예측을 얼마나 확신 하는지에 대한 지표
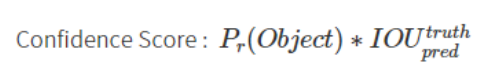
- Pr : Grid Cell 내에 물체가 존재할 확률 (존재하면 1, 존재하지 않으면 0)
- confidence가 0.5 이하인 Bbox는 모두 삭제(0.5라는 기준은 사용자 지정 가능)
- 또한 confidence가 가장 높은 Bbox만 남기고, 중복된다면 첫번째를 제외한 나머지 Bbox들은 삭제하여 한 객체당 하나의 Bbox만 남김
v2
- Bbox의 개수를 늘리고 GoogLeNet 대신 Darknet-19 모델을 사용하는 등 v1에 비해 mAP 향상
- Multi-Scaling기법을 사용하여 v1의 문제점인 작은 객체에 대한 인식률 향상
v3
- Darknet-53 모델로 변경하고 내부 구조를 조정하여 FPS를 2배 이상 향상
- 특성맵의 크기를 조절하여 크기가 큰 객체의 검출 성능 향상
-
다수의 객체 예측 시 softmax 대신 개별 클래스별 sigmoid를 활용하여 검출
(하나의 Bbox안에 복수의 객체가 존재하는 경우 softmax의 성능이 떨어짐)
v4
- CSPDarknet53, SPP, PAN, BoF, Bos 등의 기법을 통해 v3에 비해 mAP, FPS를 각각 10%, 12%씩 향상
v5 ~ v6
- 논문 없이 깃 허브로 코드만 공유
- V4에 비해 낮은 용량, 빠른 속도(높은 FPS), 비슷한 성능(mAP)
- Darknet 대신 Pytorch로 구현
- 검출되는 객체의 크기 별 전용 버전인 s, m, l, x로 버전 세분화
- Pascal VOC 데이터 셋 대신 COCO 데이터 셋(20만개, 클래스 80개)으로 훈련
v7
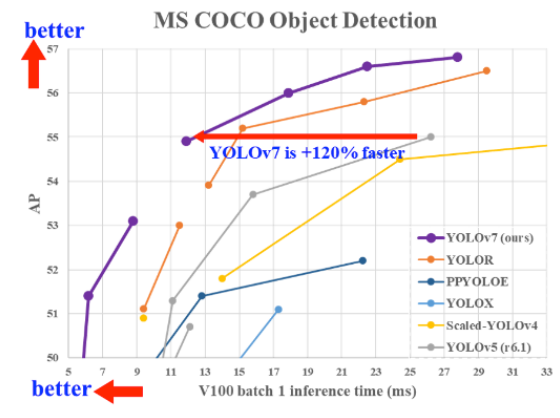
- COCO 데이터 셋 기준 30FPS 이상의 실시간 감지에서 AP 56.8%로 Yolo버전 중 가장 높음
- 인간의 포즈를 추정할 수 있는 포즈추정 모델 포함(Yolo에서 첫 등장)
댓글남기기