
RNN 순환 신경망 정리
RNN의 필요성
- 문장을 듣고 무엇을 의미하는지 알아야 하는 서비스 제공이 가능해진다.
- 문장을 듣고 이해한다는 것은 많은 문장을 이미 학습해 놓았다는 것이다.
- 문장의 의미를 전달하려면 각 단어가 정해진 순서대로 입력되어야 한다.
- 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계를 고려해야 하는 문제가 생긴다.
- 시간적 개념이 들어간 데이터들을 해결하기 위해 순환신경망(RNN)이 고안되었다.
순환신경망과 일반신경망의 차이
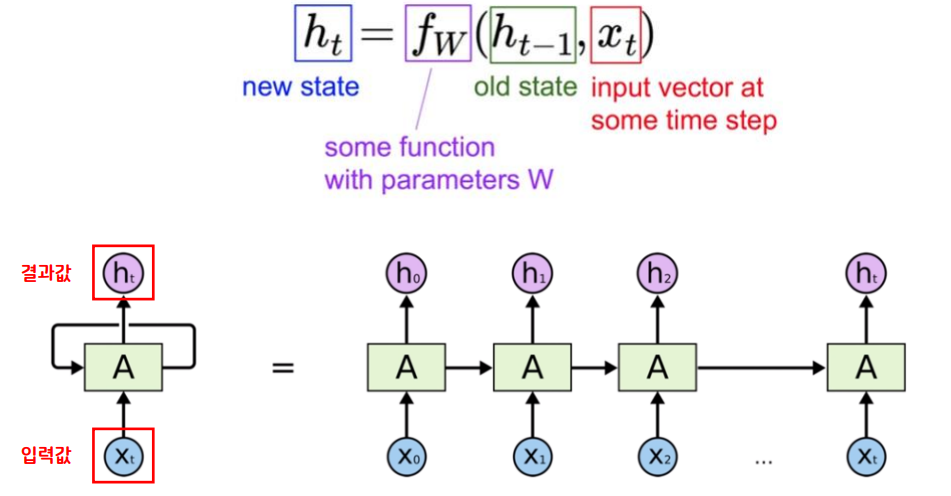
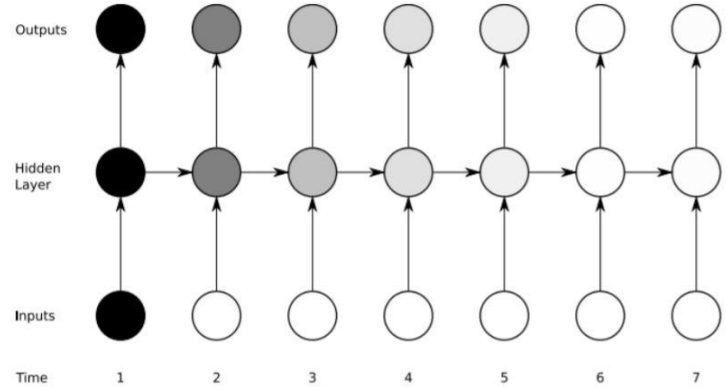
- RNN은 여러 개의 데이터가 순서대로 입력되었을 때 앞서 입력 받은 데이터의 연산 결과를 잠시 기억해 놓는 방식이다.
- 기억된 데이터를 가지고 다음 데이터로 넘어가면서 함께 연산한다.
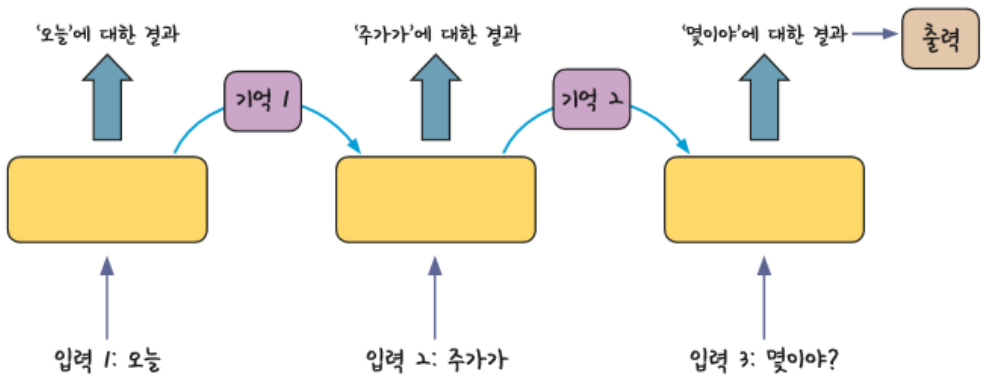
- 앞에서 나온 입력에 대한 결과가 뒤에서 나오는 입력 값에 영향을 주는 것을 알 수 있다.
- 예를 들어, 비슷한 두 문장이 입력되어도 앞에서 나온 입력 값을 구별하여 출력 값에 반영할 수 있다.
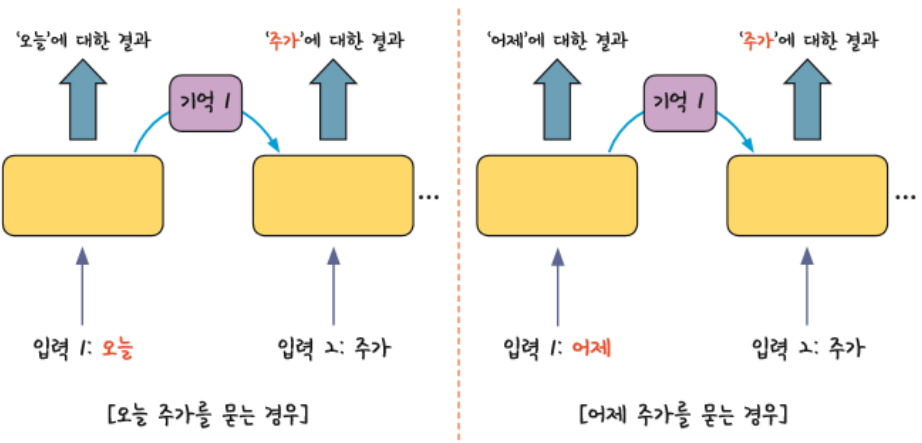
- 모든 입력 값에 이 작업을 순서대로 실행하므로 같은 층을 맴도는 것처럼 보인다.
- 같은 층안에서 맴도는 성질때문에 순환 신경망이라고 부른다.
RNN 활용 데이터 종류
: 분석에 사용되는 특성들이 시간적, 순차적 특징을 지닌 데이터에 RNN 기법이 활용된다.
- 시계열 데이터
- 음악 데이터
- 문장(자연어) 데이터
- 번역 기술 등
RNN 수식 살펴보기
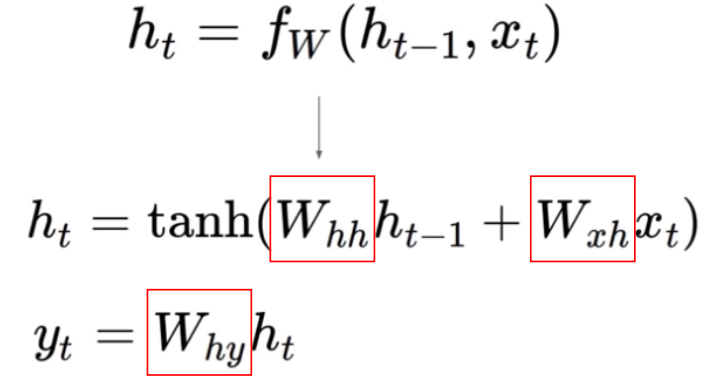
- 지금까지 신경망에서는 대부분 높은 성능을 위해 활성화 함수로 relu를 사용하였다.
- 하지만, RNN에서는 이전 가중치를 기억해야하는데, relu는 0보다 작으면 0으로 만들어버리는 성질로 인해 이전 가중치에 대한 정보를 유지할 수 없다.
- 따라서, RNN에서는 -1 ~ 1 값을 가지는 하이퍼볼릭 탄젠트(tanh)를 사용한다.
RNN 기본 신경망(SimpleRNN) 코드
SimpleRNN(units=3, imput_shape=(4, 9))
- units : 퍼셉트론(뉴런의 개수)
- input_shape : (timesteps, features) 형태의 튜플로 들어감
- timesteps : 순환 횟수 설정, 입력 시퀀스의 크기가 된다.
RNN 데이터 구조
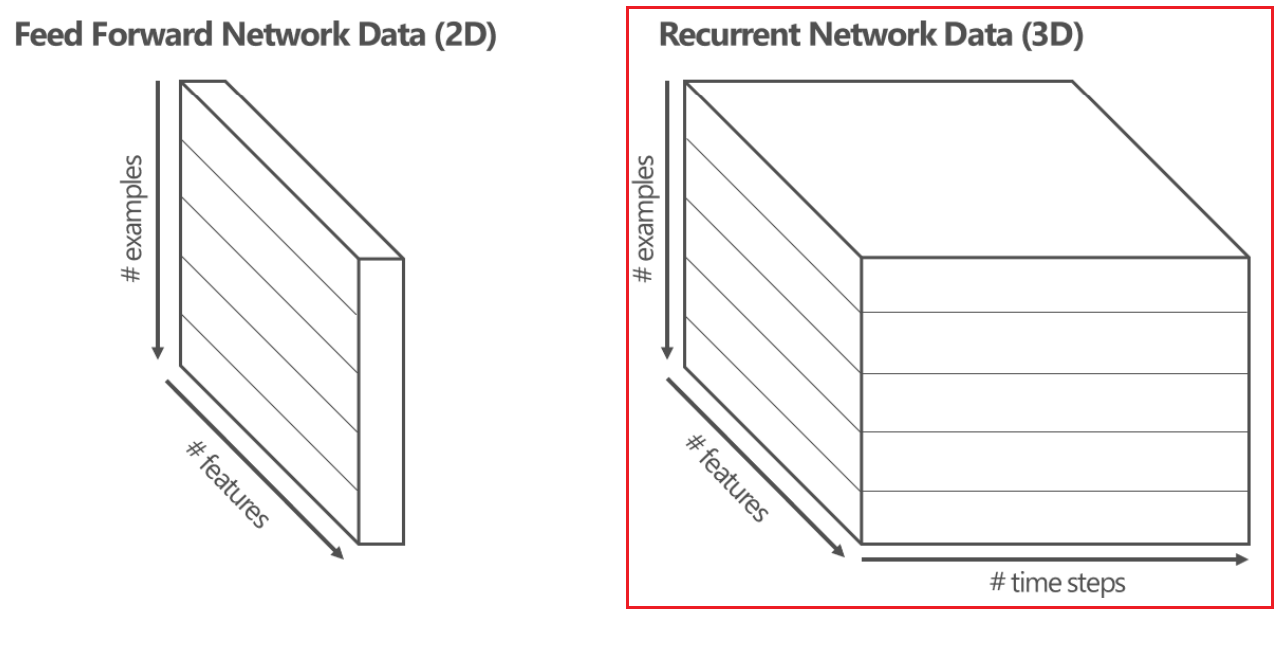
- features : 특성의 갯수
- examples : 데이터 갯수
- timesteps : 시간의 순서
RNN 활용 구조
1. 다수 입력 단일 출력
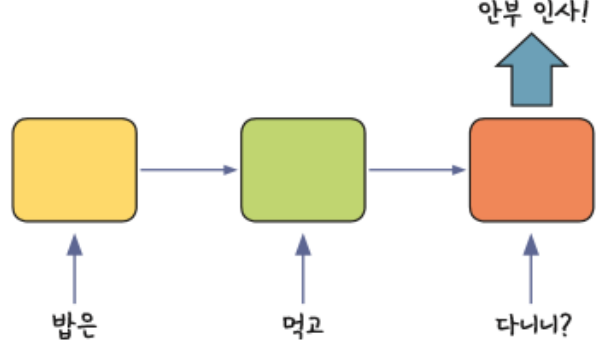
- ex) 문장을 읽고 뜻을 파악할 때 활용 가능
model = Sequential()
model.add(SimpleRNN(units = output_size,
input_shape=(timesteps, features)))
2. 단일 입력 다수 출력
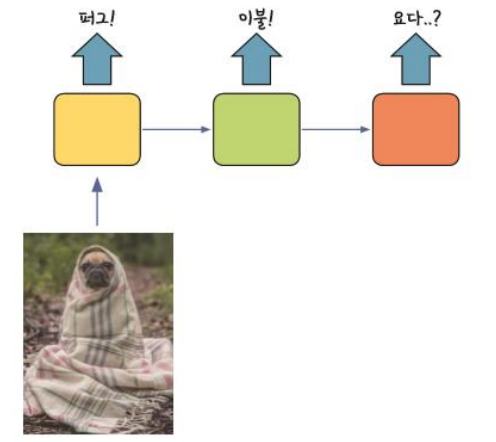
- ex) 사진의 캡션을 만들 때 활용 가능
model = Sequential()
model.add(RepeatVector(number_of_times,
input_shape=input_shape))
model.add(SimpleRNN(units = output_size,
return_sequences=True))
※ number_of_times : 출력 개수 설정, ex) 3개의 캡션을 원하면 3으로 설정
※ return_sequences=True : SimpleRNN 신경망이 순환하며 단일 값을 계속 출력
3. 다수 입력 다수 출력
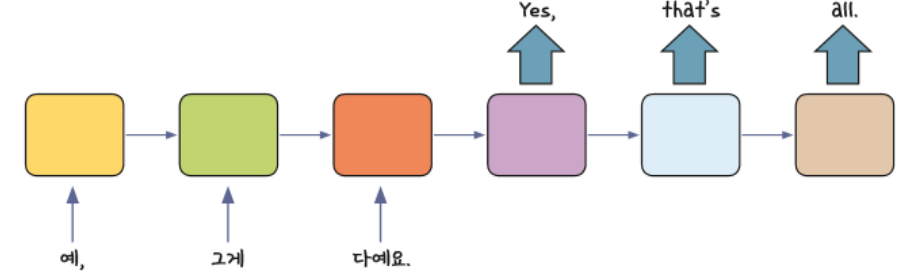
- ex) 문장을 번역할 때 활용, Video에서 Frame 단위 분류에 활용 가능
- RNN층을 여러개 쌓기 위해서 활용 가능
- 여러 층으로 쌓기 위해서는 이전 RNN층이 다수입력 다수출력 상태가 되어야한다.
- 그래야 다음 RNN층의 input 형태가 이전 RNN층과 같은 형태가 되기 때문이다
model = Sequential()
model.add(SimpleRNN(units = output_size,
input_shape=(timesteps, features),
return_sequences=True))
Simple RNN의 문제점
장기 의존성 문제(Long-Term Dependency)
활성화 함수로 tanh를 사용하기 때문에 timesteps(순환횟수)가 길어질수록 역전파시 기울기가 점차 줄어 학습 능력이 저하된다
→ 기울기 소실 문제 발생
→ 시간이 지나면 이전의 입력값을 잊어버리게 된다.
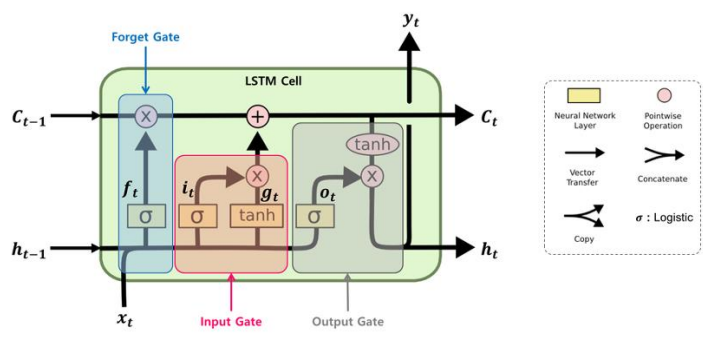
LSTM (Long Short Term Memory)
: RNN의 문제점을 극복하기 위해 나온 대안
-
- 순환횟수가 많더라도 앞에서 연산한 결과를 장기간 유지할 수 있는 ‘구조’가 필요
- RNN에 메모리 셀(cell) 추가
- 장기기억과 단기기억의 중요성을 계산해준다.
- 메모리 셀(cell)
- 시각 t에서 메모리 셀의 c에는 과거로부터 현재시각 t까지의 필요한 대부분의 정보가 저장
- 오차역전파 시 tanh와 같은 활성화 함수를 통과하지 않아서 기울기 소실이 일어나지 않음
- 데이터를 LSTM 계층 내에서만 주고 받으며 다른 계층으로는 전달하지 않음
LSTM의 구조
- LSTM 1개는 3개의 gates(forget, input, output)로 구성
- forget gate는 이전 상태 정보를 얼마나 버리고 얼마 만큼을 저장할지 결정하고,
- Input gate는 입력되는 새로운 정보를 얼마만큼 저장할지 결정하며,
- output gate는 현재 LSTM 셀의 어떤 부분을 다음 LSTM 셀로 전달할지를 결정
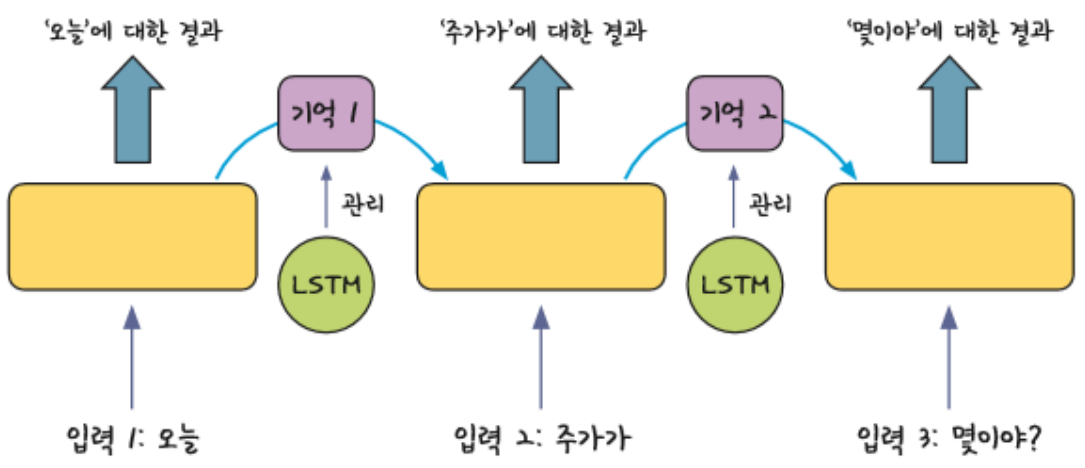
- h는 단기 상태(Short-Term state)를 c는 장기 상태(Long-Term state)라고 볼 수 있음
- 이전 스텝의 장기 기억 ct -1은 왼쪽에서 오른쪽으로 통과하면서 Forget gate를 지나면서 일부 정보를 잃고(sigmoid가 곱해지므로), Input gate로부터 덧셈(+) 연산을 통해 새로운 정보를 추가하여 현재 타임 스텝의 장기 기억 ct 가 생성 됨
- ct는 Output gate의 tanh 함수로 전달되어 단기 상태 ht를 만듦
- LSTM의 복잡성을 줄여 속도측면에서 더 빠른 효과를 볼 수 있는 GRU가 존재(목적에 맞는 속도에 따라 LSTM / GRU 선택)
다중 LSTM Layer
- LSTM층 또한, RNN과 마찬가지로 다중으로 쌓기 위해서는 이전 LSTM층이 다수입력 다수출력 상태가 되어야한다.
- 그래야 다음 RNN층의 input 형태가 이전 RNN층과 같은 형태가 되기 때문이다
- LSTM, RNN층에서 순환할때마다 출력값을 만들어주는 return_sequences=True 옵션을 사용해야함
워드 임베딩(Word Embedding)
- 컴퓨터가 자연어를 이해하고 효율적으로 처리하기 위해서는 단순한 인코딩이 아닌 컴퓨터가 더 잘 이해할 수 있도록 변환 할 필요가 있음
- 워드 임베딩은 한 단어의 의미를 풍부하게 만들어주는역할(특성을 늘려주는 역할)을 함
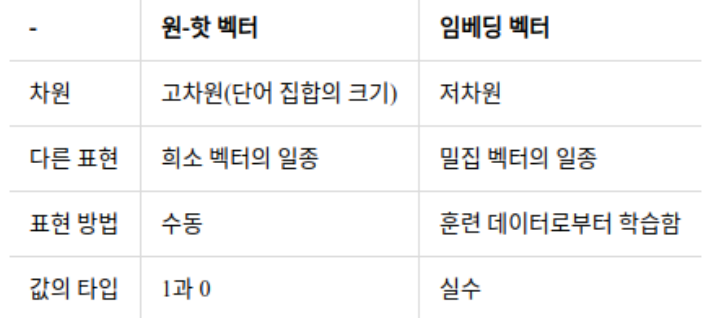
- 주로 희소 표현(원 핫 인코딩)에서 밀집 표현(실수형태)으로 변환하는 것을 의미
- 밀집표현을 통해 해당 단어와 유사한 다른 단어들의 수치(유사도)까지 표시함
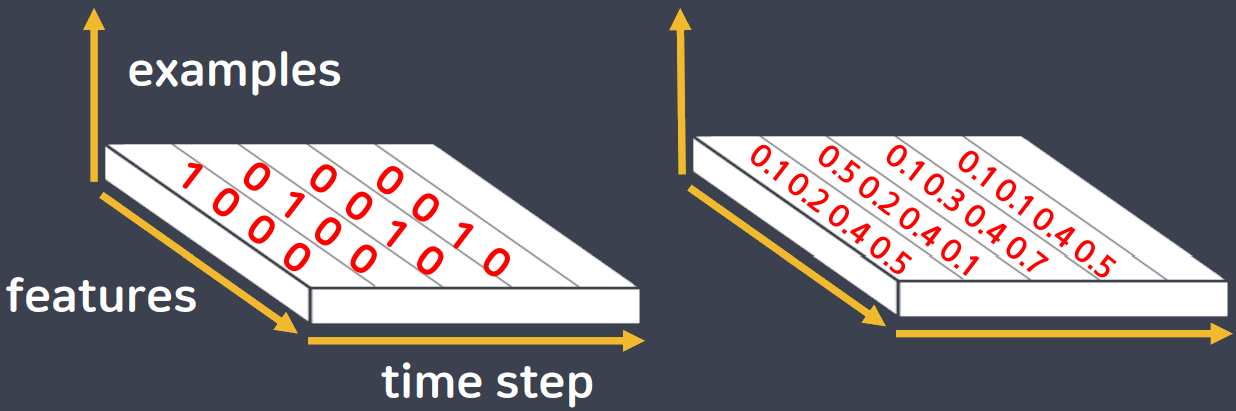
- 임베딩 과정을 통해 나온 결과를 임베딩 벡터(embedding vector)라고 함
- 케라스에도 제공하는 도구인 Embedding()은 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하게 됨
Embedding 사용
- Embedding(사용하는 단어사전의 수, 한 단어를 표현할 특징의 수)을 순환신경망층 가장 앞에 추가하기
- 사용하는 단어 사전의 수는 학습에 사용되는 단어의 갯수이다
- 한 단어를 표현할 특징의 수는 적절한 수로 설정해서 모델이 알아서 특징을 검출하게 해준다
순환 신경망 사용해보기 (SimpleRNN)
1. 데이터 직접 준비
- 5개의 단어로 문자 하나하나를 단위로 하여 RNN을 사용해보기
- “hello”, “apple”, “lobby”, “daddy”, “bobby”
- 문제 데이터 : “hell”, “appl”, “lobb”, “dadd”, “bobb”
- 정답 데이터 : “o”, “e”, “y”, “y”, “y”
입력 데이터의 문자 갯수는 모두 4개이므로, timesteps(순환 횟수)를 4로 설정
학습을 위해 문자 데이터를 숫자 데이터로 인코딩하기
- RNN 데이터의 구조를 파악하기 위해 직접 one-hot 인코딩 수행
- 문제, 정답 데이터에 등장하는 모든 문자(unique value)는 h, e, l, o, a, p, b, y, d로 총 9개이다.
- h : [1,0,0,0,0,0,0,0,0]
- e : [0,1,0,0,0,0,0,0,0]
- l : [0,0,1,0,0,0,0,0,0]
- o : [0,0,0,1,0,0,0,0,0]
- a : [0,0,0,0,1,0,0,0,0]
- p : [0,0,0,0,0,1,0,0,0]
- b : [0,0,0,0,0,0,1,0,0]
- y : [0,0,0,0,0,0,0,1,0]
- d : [0,0,0,0,0,0,0,0,1]
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 문제 데이터
X_train = np.array(
[
# 각각의 단어들
[[1,0,0,0,0,0,0,0,0],[0,1,0,0,0,0,0,0,0],[0,0,1,0,0,0,0,0,0],[0,0,1,0,0,0,0,0,0]], # h, e, l, l
[[0,0,0,0,1,0,0,0,0],[0,0,0,0,0,1,0,0,0],[0,0,0,0,0,1,0,0,0],[0,0,1,0,0,0,0,0,0]], # a, p, p, l
[[0,0,1,0,0,0,0,0,0],[0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,1,0,0]], # l, o, b, b
[[0,0,0,0,0,0,0,0,1],[0,0,0,0,1,0,0,0,0],[0,0,0,0,0,0,0,0,1],[0,0,0,0,0,0,0,0,1]], # d, a, d, d
[[0,0,0,0,0,0,1,0,0],[0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,1,0,0]] # b, o, b, b
])
# 정답 데이터
y_train = np.array(
[
[0,0,0,1,0,0,0,0,0], # o
[0,1,0,0,0,0,0,0,0], # e
[0,0,0,0,0,0,0,1,0], # y
[0,0,0,0,0,0,0,1,0], # y
[0,0,0,0,0,0,0,1,0] # y
])
X_train.shape, y_train.shape
((5, 4, 9), (5, 9))
데이터 구조 확인
- 문제 데이터의 크기 = (samples, timesteps, features) = (5, 4, 9)
- 5 : samples, 데이터의 갯수
- 4 : timesteps, 순환 횟수
- 9 : features, 특성 수(원핫 인코딩된 컬럼 수)
- 출력되는 정답을 알파벳 전체로 하고 싶다면 26개로 원핫 인코딩을 시켜주면 됨
- 현재는 간단한 실습을 위해 9개의 문자로만 문제와 정답 설정
2. RNN 신경망 모델링
- SimpleRNN(units, input_shape=(timesteps, features))
- units : 퍼셉트론(뉴런의 개수)
- input_shape : (timesteps, features) 형태의 튜플로 들어감
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
model = Sequential()
model.add(SimpleRNN(8, input_shape=(4, 9))) # 입력층 + 중간층
model.add(Dense(9, activation='softmax')) # 출력층
- 입력 시퀀스의 크기(순환 해야하는 횟수가 됨)는 4, 입력 데이터의 특성은 9 이므로 input_shapes = (4, 9)
- RNN층(중간층)에 사용되는 뉴런은 8개이다.
- 9개의 특성에서 정답을 맞춰야 하므로 출력층의 뉴런은 9이다.
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_2 (SimpleRNN) (None, 8) 144
dense_2 (Dense) (None, 9) 81
=================================================================
Total params: 225
Trainable params: 225
Non-trainable params: 0
_________________________________________________________________
RNN은 가중치가 두 종류가 존재한다 (과거 데이터의 가중치, 현재 데이터의 가중치)
-
현재 데이터의 가중치
→ 9(입력 특성) X 8(RNN층 뉴런 수) + 8(RNN층 뉴런 수) = 80
-
과거 데이터의 가중치
→ 8(RNN층 뉴런 수) X 8(RNN층 뉴런 수) = 64
- RNN층의 순환 횟수와는 상관없이 최종적으로 출력되는 연산 결과에만 가중치가 존재하므로
-
파라미터 갯수 → 80 + 64 = 144
모델 컴파일 및 학습
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
h = model.fit(X_train, y_train, epochs=300)
학습 현황 시각화
plt.figure(figsize=(15, 5))
plt.plot(h.history['acc'], label='acc', marker='.')
plt.legend()
plt.show()

댓글남기기