
LSTM과 GRU를 사용한 IMDB 분류
LSTM
RNN은 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우 역전파시 그래디언트가 점차 줄어 학습능력이 떨어진다고 알려져 있습니다. (vanishing gradient problem)
이 문제를 보완하기 위해 LSTM이 등장합니다.
LSTM(Long Short Term Memory)는 기존의 RNN이 출력과 먼 위치에 있는 정보를 기억할 수 없다는 단점을 보완한 방법입니다.
장기 / 단기 기억을 가능하게 설계한 신경망의 구조입니다.
주로 시계열, 자연어 처리에 사용됩니다.
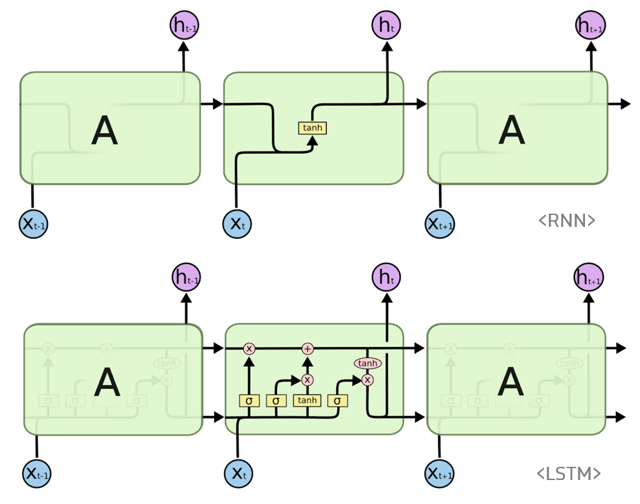
LSTM의 구조
LSTM은 RNN과 다르게 한 개의 tanh layer가 아닌 4개의 layer로 구성되어 서로 정보를 주고 받는 방식입니다.
또한, LSTM 셀에서는 상태가 크게 두 가지의 상태가 순환합니다.
RNN의 은닉 상태(hidden state)에 셀 상태(cell state)가 추가됩니다.
LSTM의 출력으로 사용되는 것은 은닉 상태, 셀 상태는 셀 안에서 순환하는 상태입니다.
<이미지 출처 : https://imgur.com/jKodJ1u>
여기서 LSTM 모듈에는 4개의 layer가 존재하는 것을 알 수 있습니다.
LSTM 과정

노란색 박스는 학습된 neural network layer이고, 분홍색 동그라미는 vector 연산과 같은 pointwise operation을 나타냅니다.
합쳐지는 선은 concatenateion을 의미하고, 갈라지는 선은 정보를 복사해서 다른쪽으로 보내는 fork입니다.
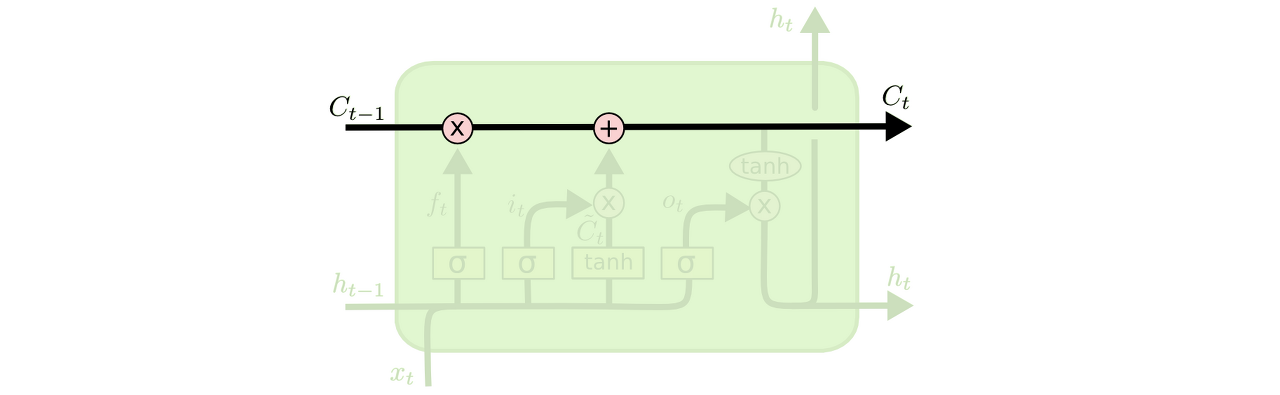
Cell state는 모듈 상단에 수평으로 그어진 윗 선에 해당됩니다.
Cell state는 컨베이어 벨트와 같이, 정보가 전혀 바뀌지 않고 그대로 흐르게만 하는 역할을 합니다.
LSTM은 Cell state에 뭔가를 더하거나 없애는 과정을 반복합니다. 이 과정에서 3가지의 gate를 사용합니다.
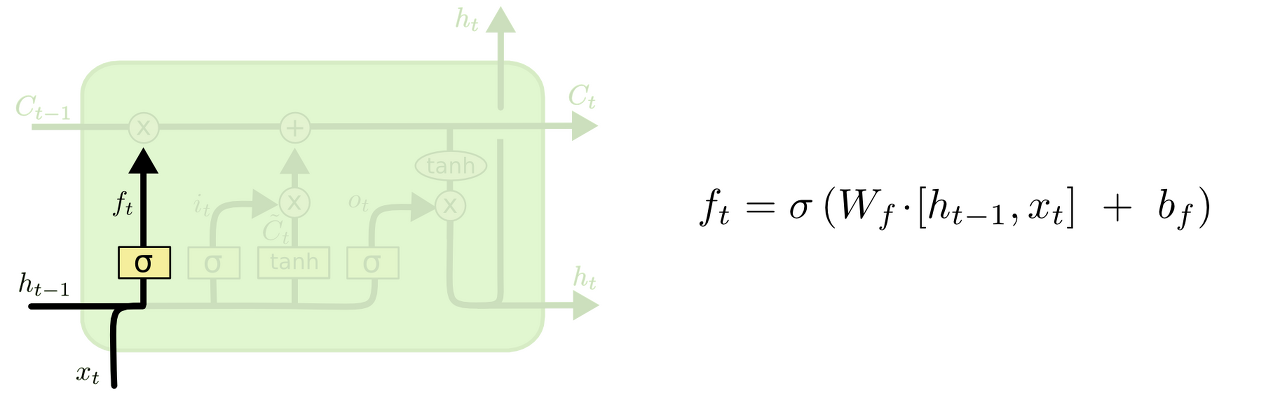
LSTM의 첫 단계로 Cell state로부터 어떤 정보를 버릴 것인지 정하는 forget gate 입니다.
ht-1과 xt를 받아 시그모이드를 취해(0 ~ 1값) ct-1에 보내줍니다.
이 값이 1이면 “모든 정보 전달”, “0이면 모두 버리기”가 됩니다.
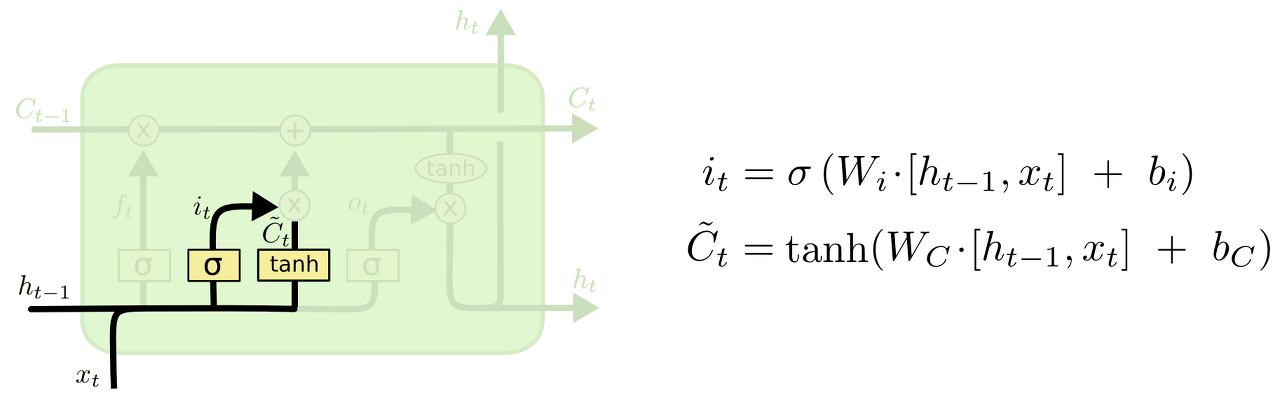
다음 단계는 입력되는 새로운 정보 중 어떤 것을 Cell state에 저장할 것인지 정하는 input gate 입니다.
먼저 sigmoid layer가 어떤 값을 업데이트할 지 정하고, 그 다음에 tanh layer가 새로운 후보 값 c~t라는 vector를 만들고 Cell state에 더할 준비를 합니다.
이렇게 두 단계에서 나온 정보를 합쳐서 state에 업데이트할 준비를 합니다.
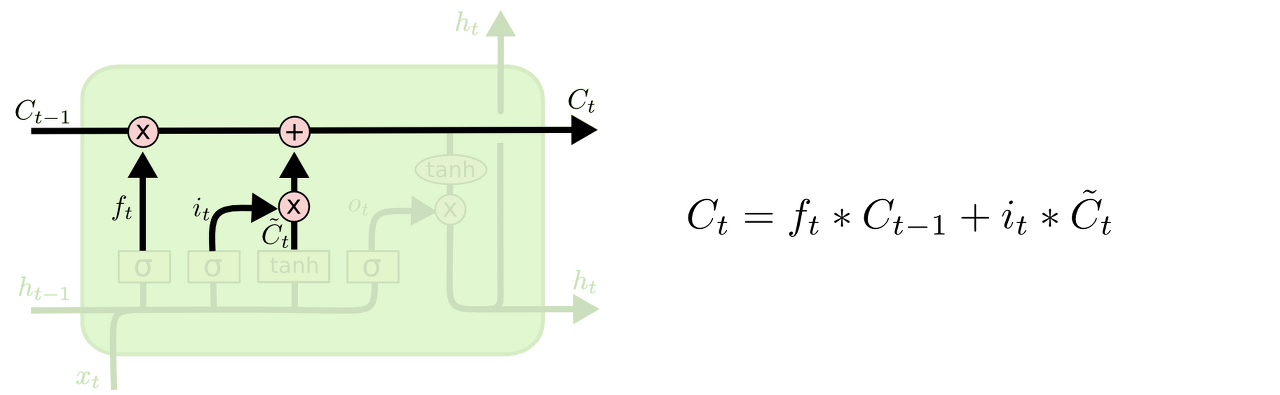
이전 state인 ct-1에 ft를 곱해서 forget gate에서 잊어버리기로 정했던 정보들을 모두 잊어버립니다.
그리고나서 it x c~t를 더해줍니다. 이 더한 값은 두번째 단계에서 업데이트하기로 한 값을 얼마나 업데이트할 지 정한 만큼 scale한 값이 됩니다.
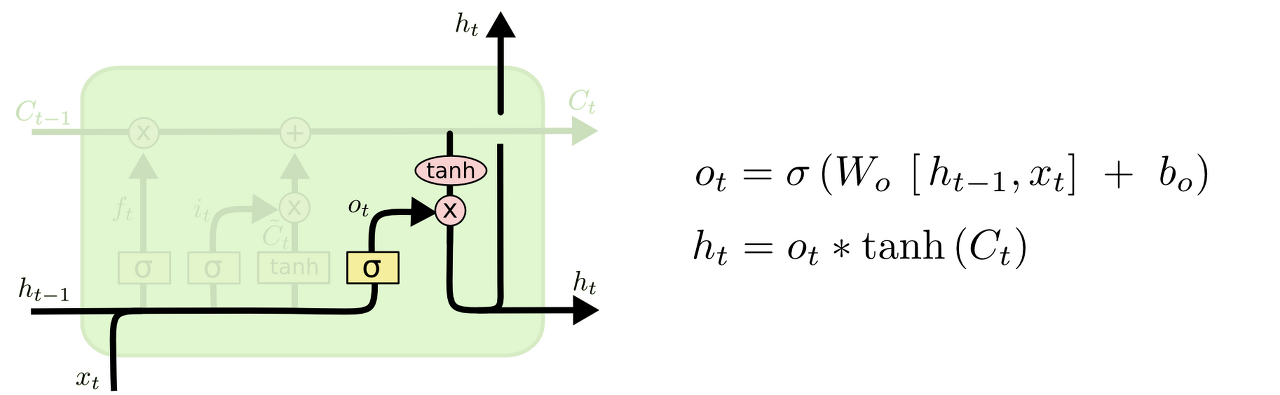
마지막으로 출력으로 내보내는 output gate 입니다.
먼저, sigmoid layer에 input 데이터를 넣어서 Cell state의 어느 부분을 ouput으로 보낼지 정합니다.
그리고 Cell state를 tanh layer에 전달해서 -1과 1사이의 값을 받은 뒤에 방금 전의 sigmoid layer의 output과 곱합니다.
그 후, ouput으로 보내게 됩니다.
GRU 셀
GRU 셀은 LSTM 셀에서 좀 더 간소화된 구조라고 말할 수 있습니다.
LSTM에 비해 Gate가 2개이며 reset gate(r)와 update gate(z)로 이루어집니다.
-
reset gate는 이전 상태를 얼마나 잊어버릴지를 결정합니다.
-
update gate는 이전 상태와 현재 상태를 얼마만큼의 비율로 반영할지를 결정합니다.
LSTM 셀에 존재하는 cell state와 hidden state가 하나로 합쳐집니다.
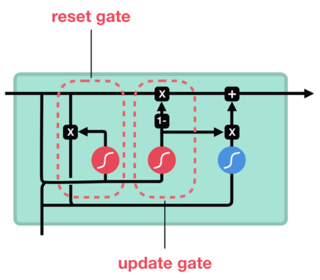
Input
이전 시점의 셀에서 전달된 hidden state(h(t-1))와 새로운 input값인 x(t)가 합쳐지고 두 방향으로 나뉘어 전달됩니다.
하나는 게이트에 전달될 정보가 되고, 다른 하나는 LSTM의 Candidate state의 역할을 합니다.
reset gate
이전 상태의 은닉 상태와 현재 상태의 x를 받아 sigmoid처리를 합니다.
candidate state(h_hat(t))에 전달되는 데이터에 어떤 정보를 지우고, 어떤 정보를 전달할지 결정합니다.
update gate
이전 상태의 은닉 상태와 현재 상태의 x를 받아 sigmoid처리를 합니다.
LSTM 셀의 forget과 input 게이트와 비슷한 역할을 하지만, Update 되는 정보의 양에 1이라는 제한이 있습니다.
이전 정보인 h(t-1)과 reset gate를 지나온 candidate state(h_hat(t))에 동시에 전달되는데,
이때 한쪽에 x의 크기가 전달되면, 반대쪽은 1-x만큼 전달됩니다.
즉, 정보를 지운만큼만 새로운 정보를 입력하고, 새로운 정보를 입력한 만큼 정보를 지울 수 있습니다.
candidate state
현재 셀에 입력된 정보 중에서 Output과 다음 셀로 전달할 중요한 후보 정보를 담고 있는 state입니다.
reset gate를 거친 정보들은 tanh함수를 취해 update gate까지 지나며 h(t-1)과 합쳐집니다.
hidden state
LSTM의 cell state의 역할까지 동시에 합니다.
update gate를 통과하면서 의미 없는 데이터를 삭제하고 현재 셀의 중요한 정보를 담고 있는 candidate state와
합쳐져 output이 되고, 동시에 다음 시점의 셀로 정보를 전달합니다.
LSTM 신경망으로 IMDB 예측
이전에 SimpleRNN과 Embedding을 사용하여 예측했던 IMDB 데이터 분류를 LSTM을 사용하여 다시 분류해보겠습니다.
데이터 처리 과정은 이전과 동일하게 수행하겠습니다.
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.sequence import pad_sequences
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=10000)
X_train_seq = pad_sequences(X_train, maxlen=500)
X_test_seq = pad_sequences(X_test, maxlen=500)
X_train_seq, X_val_seq, y_train, y_val = train_test_split(X_train_seq, y_train)
X_train_seq.shape, X_val_seq.shape
((18750, 500), (6250, 500))
model = keras.Sequential()
model.add(keras.layers.Embedding(10000, 16, input_length=500))
model.add(keras.layers.LSTM(8))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 500, 16) 160000
lstm_2 (LSTM) (None, 8) 800
dense_1 (Dense) (None, 1) 9
=================================================================
Total params: 160,809
Trainable params: 160,809
Non-trainable params: 0
_________________________________________________________________
summary 정보에서 파라미터 갯수를 확인해보면 embedding층에서는 10000 x 16개,
LSTM층에서는 embedding층의 출력인 16이 입력이 되어 8개의 뉴런과 완전 연결되어 16 x 8,
은닉 상태의 셀이 순환되어 8 x 8, 그리고 절편 8개를 포함하여 200개가 되는데 LSTM은 4개의 layer가 존재하므로
200 x 4 = 800이 되는 것을 확인할 수 있습니다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop,
loss='binary_crossentropy',
metrics=['acc'])
checkpoint = keras.callbacks.ModelCheckpoint('./models/imdb10000-lstm-model.h5')
early_stopping = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model.fit(X_train_seq, y_train, epochs=100, batch_size=64, verbose=0,
validation_data=(X_val_seq, y_val),
callbacks=[checkpoint, early_stopping])
model.evaluate(X_test_seq, y_test)
782/782 [==============================] - 13s 17ms/step - loss: 0.3348 - acc: 0.8679
[0.33479073643684387, 0.8679199814796448]
# 손실과 정확도 시각화
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='orange', label='val_loss')
ax1.set_title('train and val loss')
ax1.set_xlabel('epochs')
ax1.set_ylabel('loss')
ax1.legend()
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, acc, color='green', label='train_acc')
ax2.plot(epochs, val_acc, color='red', label='val_acc')
ax2.set_title('train and val acc')
ax2.set_xlabel('epochs')
ax2.set_ylabel('acc')
ax2.legend()
<matplotlib.legend.Legend at 0x7f9f33e88520>

Dropout 추가
이전에 구성했던 모델을 좀 더 정확한 예측을 위해 신경망을 좀 더 깊게 수정하고 Dropout을 추가해보았습니다.
LSTM층에서 다음 LSTM층을 쌓아 연결할때는, 각 타임 스텝의 은닉상태를 모두 출력해주어야 마지막에 있는 순환 셀이 제대로 동작할 것입니다.
기본적으로 keras의 순환층은 마지막 타임 스텝의 은닉상태만 출력하기 때문에 모든 타임 스텝마다 은닉상태를 출력해주기 위해 return_sequences=True를 설정해주어야 합니다.
LSTM에서 Dropout을 사용할 땐 따로 층을 추가하지 않고 매개변수로서 추가를 해줘야 합니다.
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.sequence import pad_sequences
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=10000)
X_train_seq = pad_sequences(X_train, maxlen=500)
X_test_seq = pad_sequences(X_test, maxlen=500)
X_train_seq, X_val_seq, y_train, y_val = train_test_split(X_train_seq, y_train)
X_train_seq.shape, X_val_seq.shape
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
((18750, 500), (6250, 500))
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(10000, 16, input_length=500))
model2.add(keras.layers.LSTM(8, dropout=0.3, return_sequences=True))
model2.add(keras.layers.LSTM(8, dropout=0.3))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop,
loss='binary_crossentropy',
metrics=['acc'])
checkpoint = keras.callbacks.ModelCheckpoint('/content/gdrive/MyDrive/models/imdb10000-lstm-model.h5')
early_stopping = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model2.fit(X_train_seq, y_train, epochs=100, batch_size=64, verbose=0,
validation_data=(X_val_seq, y_val),
callbacks=[checkpoint, early_stopping])
model2.evaluate(X_test_seq, y_test)
782/782 [==============================] - 52s 67ms/step - loss: 0.3029 - acc: 0.8813
[0.302852600812912, 0.8813199996948242]
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, acc, color='blue', label='train_loss')
ax1.plot(epochs, val_acc, color='orange', label='val_loss')
ax1.set_title('train and val acc')
ax1.set_xlabel('epochs')
ax1.set_ylabel('acc')
ax1.legend()
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, loss, color='green', label='train_acc')
ax2.plot(epochs, val_loss, color='red', label='val_acc')
ax2.set_title('train and val loss')
ax2.set_xlabel('epochs')
ax2.set_ylabel('loss')
ax2.legend()
<matplotlib.legend.Legend at 0x7f8da1562a50>

드롭아웃을 적용한 모델에서 훈련 데이터와 검증 데이터의 손실값 차이가 좀 더 적게 나타난 것을 확인할 수 있습니다.
다음은 GRU셀을 이용해서 동일한 방법으로 모델을 구성해보았습니다.
model3 = keras.Sequential()
model3.add(keras.layers.Embedding(10000, 16, input_length=500))
model3.add(keras.layers.GRU(8, dropout=0.3, return_sequences=True))
model3.add(keras.layers.GRU(8, dropout=0.3))
model3.add(keras.layers.Dense(1, activation='sigmoid'))
model3.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 500, 16) 160000
gru_2 (GRU) (None, 500, 8) 624
gru_3 (GRU) (None, 8) 432
dense_3 (Dense) (None, 1) 9
=================================================================
Total params: 161,065
Trainable params: 161,065
Non-trainable params: 0
_________________________________________________________________
model3.compile(optimizer=rmsprop,
loss='binary_crossentropy',
metrics=['acc'])
checkpoint = keras.callbacks.ModelCheckpoint('/content/gdrive/MyDrive/models/imdb10000-gru-model.h5')
early_stopping = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history2 = model3.fit(X_train_seq, y_train, epochs=100, batch_size=64, verbose=0,
validation_data=(X_val_seq, y_val),
callbacks=[checkpoint, early_stopping])
model3.evaluate(X_test_seq, y_test)
782/782 [==============================] - 49s 63ms/step - loss: 0.3073 - acc: 0.8774
[0.30730995535850525, 0.8773599863052368]
acc = history2.history['acc']
val_acc = history2.history['val_acc']
loss = history2.history['loss']
val_loss = history2.history['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, acc, color='blue', label='train_loss')
ax1.plot(epochs, val_acc, color='orange', label='val_loss')
ax1.set_title('train and val acc')
ax1.set_xlabel('epochs')
ax1.set_ylabel('acc')
ax1.legend()
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, loss, color='green', label='train_acc')
ax2.plot(epochs, val_loss, color='red', label='val_acc')
ax2.set_title('train and val loss')
ax2.set_xlabel('epochs')
ax2.set_ylabel('loss')
ax2.legend()
<matplotlib.legend.Legend at 0x7f8da4c6aa90>

IMDB 데이터셋을 분류할 때, LSTM 셀을 사용한 방법과 GRU 셀을 사용한 방법이 비슷한 정확도를 가질 수 있는 것을 확인했습니다.
실제로 GRU 셀을 사용했을 때 학습시간이 덜 걸린 것을 확인할 수 있었습니다.
댓글남기기