sample_data = data.iloc[[30,110,150,433,498],[2,4]]
ground_truth = data.iloc[[30,110,150,433,498],0]
# my_KNN
# 입력 변수 (예측할 데이터 샘플, k값)
def my_KNN(input_data, k):
# 카운터 딕셔너리
from collections import Counter
# 1. 모든 데이터와 input데이터 사이의 거리계산
distance_list = []
for i in range(len(input_data)):
temp = (X - input_data.iloc[i]) ** 2 # X데이터 전체[키, 몸무게] - i번째 인풋[키, 몸무게] -> 결과 : [a제곱, b제곱]
distance = (temp.iloc[:, 0] + temp.iloc[:, 1])**0.5 # (키 + 몸무게) 의 제곱근
distance_list.append(distance)
distance_list = pd.Series(distance_list, index=input_data.index) # list -> series 변환, 크기 : 샘플데이터 갯수 X 500
#print(distance_list)
# 2. k값만큼 가장 가까운 거리의 데이터 추출
k_neighbors = []
for i in range(len(input_data)):
input_i = distance_list.iloc[i]
temp = []
for j in range(k):
# k개만큼 최솟값들 뽑기
#idx = input_i[input_i == input_i.min()].index[0]
idx = input_i.idxmin() # 구한 최솟값의 인덱스 구하기
temp.append(y.loc[idx])
input_i.drop([idx], inplace=True) # 최솟값 중복 없애게 이번에 뽑은 최솟값은 제거해주기
k_neighbors.append(temp) # k_neighbors -> 크기 : (샘플데이터 갯수 X k개의 최소거리 인덱스)
#print(k_neighbor)
# 3. 추출된 데이터의 비율 확인 후 예측
output = []
for nb in k_neighbors:
count = Counter(nb) # key : 결과, value: key값이 나온 갯수
output.append(max(count,key=count.get))
output = pd.Series(output, index=input_data.index) # input값의 인덱스 유지하기 위해 series화
return output
0 Obesity
1 Normal
2 Obesity
3 Overweight
4 Overweight
dtype: object
0 Obesity
1 Normal
2 Obesity
3 Overweight
4 Overweight
Name: Label, dtype: object
12 Overweight
16 Extreme Obesity
19 Extreme Obesity
21 Extreme Obesity
31 Weak
dtype: object
12 Overweight
16 Extreme Obesity
19 Extreme Obesity
21 Extreme Obesity
31 Weak
Name: Label, dtype: object

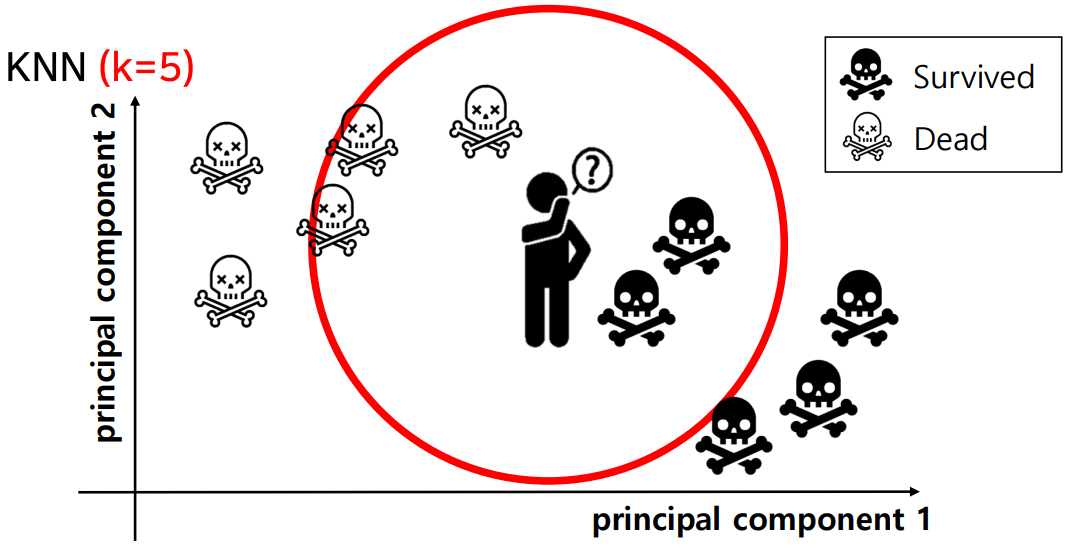
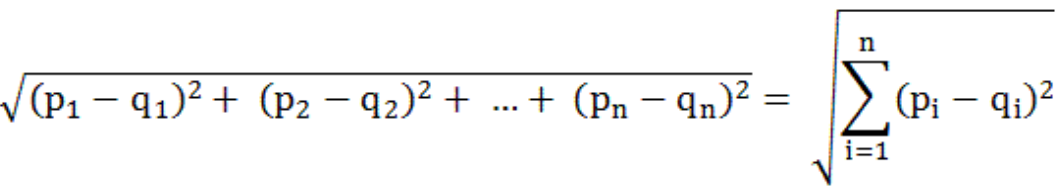
댓글남기기